
In a striking development, OpenAI’s latest model, known as “o3,” has scored on par with humans in a general intelligence benchmark. But before we declare the arrival of Artificial General Intelligence (AGI), a closer look reveals how benchmarks both guide progress and underscore just how far we still have to go.
The o3 Model and the ARC-AGI Benchmark
OpenAI’s o3 model recently achieved a breakthrough: scoring 85% on the ARC-AGI benchmark—a test designed to evaluate an AI’s ability to generalize from minimal examples, similar to solving new puzzles using limited data. This score matches average human performance and significantly surpasses prior AI models that typically scored around 55%.

ARC-AGI challenges AI to identify patterns or solve problems from just a few visual examples—much like grid-based intelligence puzzles. The standout here is not just accuracy, but adaptability with scarce information.
Does Matching the Benchmark Mean True General Intelligence?
While these results are impressive, experts caution that mastering a benchmark is not the same as possessing general intelligence. The designer of ARC-AGI himself emphasizes that passing the test is no proof of AGI; it merely indicates improved learning efficiency on this specific task.
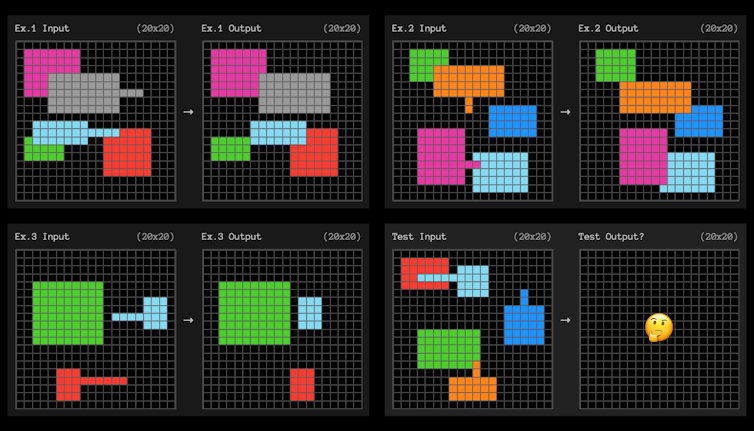
AGI implies flexible, autonomous reasoning across widely varied, real-world scenarios—something today’s systems still struggle with. They excel in structured tasks with expert training, but often fail in tasks requiring common sense, context, or long-term planning.
A Step, Not a Milestone
This milestone signifies that AI is improving—especially expecting fewer examples to generalize effectively—but we must resist overselling it. AGI remains more aspirational in concept than achieved in practice.
The benchmark is a stepping-stone—evidence of progress rather than proof of completion. Each new test pushes development forward, but also reveals fresh gaps to bridge, such as autonomous learning, emotional reasoning, and real-world adaptability.
Why Benchmarks Still Matter
Benchmarks like ARC-AGI play a pivotal role in AI development. They formalize goals, spotlight emerging strengths, and highlight remaining weaknesses. When an AI like o3 performs arbitrarily well on a generalization test, it forces researchers to rethink how AI learns and adapt future tests to remain challenging and meaningful.
Still, as long as we cling to benchmarks as end-all-be-all definitions of intelligence, we risk mistaking narrow performance for broad capability. True AGI will require understanding, adaptability, learning from minimal data, self-direction, and emotional nuance—capacities that go beyond any one benchmark.



{kind=link}